IMAP-Part 07: Microbiome Data Preparation Guide
Welcome to IMAP chapter 07
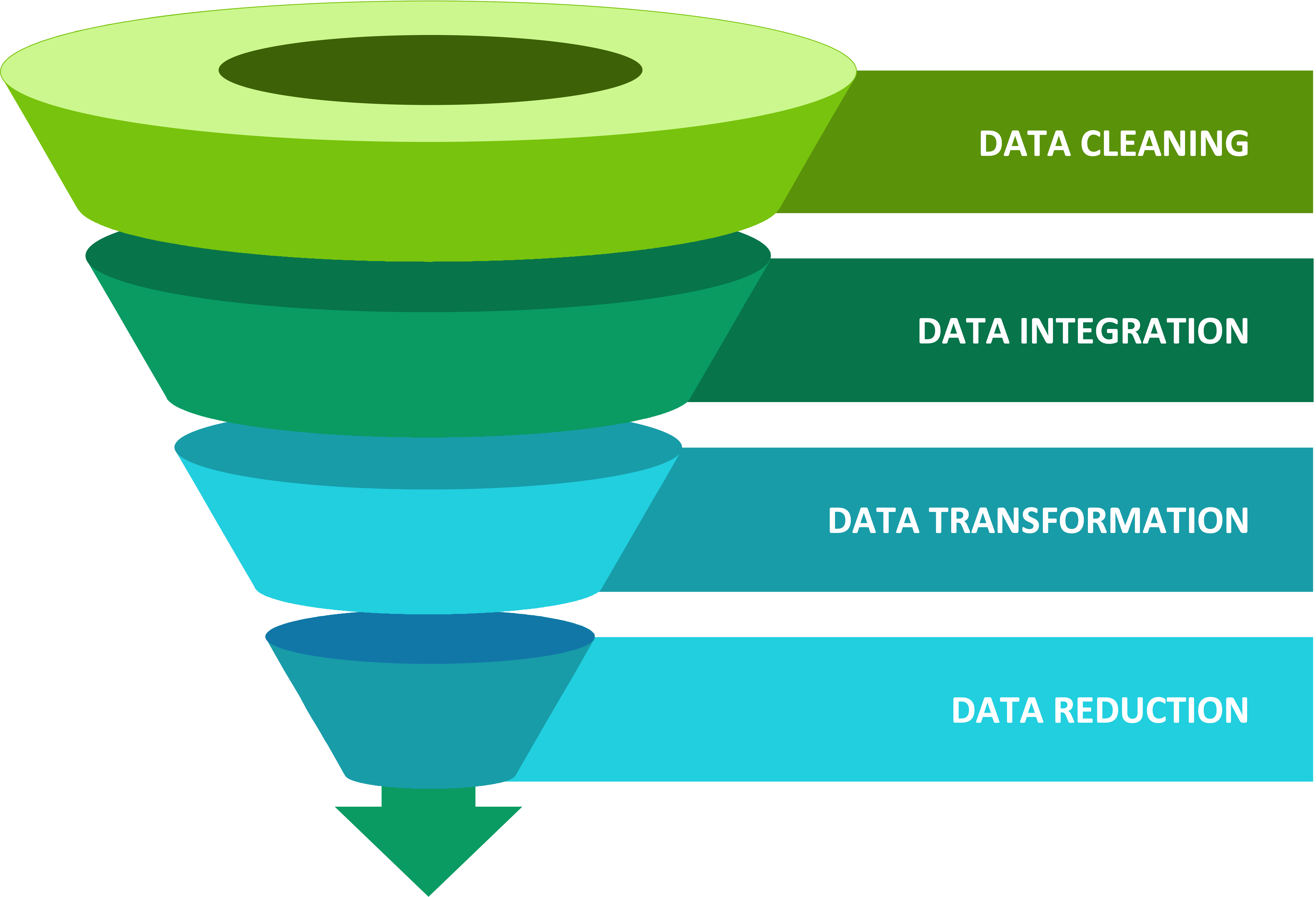
Microbiome research employs high-throughput sequencing to explore microbial communities across diverse environments. This project focuses on preparing and visualizing microbiome data generated from the Mothur and QIIME2 pipelines. The dataset comprises an OTU table, taxonomic assignments, and metadata. This comprehensive guide is tailored for researchers and analysts engaged in microbiome studies, providing essential insights and methodologies for adequate data preparation. Assuming that the bioinformatics analysis phase has been successfully completed and you now possess the output or features tables, including Operational Taxonomic Unit (OTU) tables, taxonomy tables, and a metadata table, from platforms such as Mothur or QIIME2, this guide will lead you through the crucial steps of refining and optimizing your microbiome data.
What to Expect
Before diving into the details, let’s take a look at what you can expect from this guide:
Step-by-Step Instructions: Each section of this guide presents clear and concise step-by-step instructions, ensuring seamless follow-through.
Best Practices: Discover best practices for data cleaning, transformation, and integration, emphasizing optimization of your microbiome datasets for robust analysis.
Practical Insights: Beyond technical instructions, the guide offers practical insights to navigate nuanced decisions in data preparation, empowering informed choices aligned with your research goals.
Whether you’re venturing into microbial communities for the first time or seeking advanced strategies to refine your microbiome data, this guide is your companion. Your commitment to data preparation will be pivotal in extracting meaningful biological insights and contributing to the advancement of microbiome research.
Let’s dive in!